PPO vs Advantage Actor-Critic (A2C) Reinforcement Learning-based Models
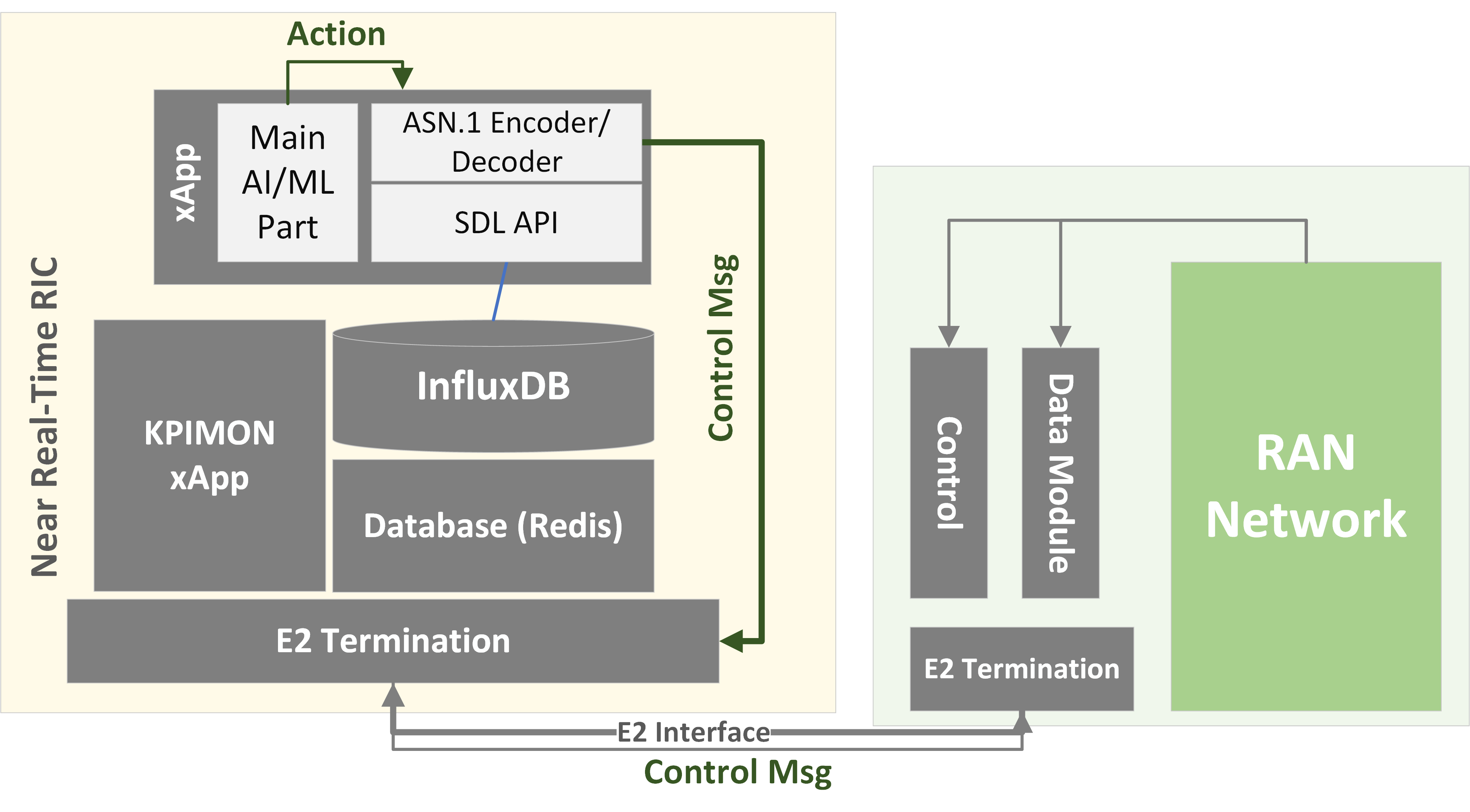
RL ComparisonThe learning problem is formulated as a Markov Decision Process (MDP), where the xApp observes the network state, chooses a scheduling action, receives reward, and updates its policy to maximize long-term QoE. Both A2C and PPO belong to the actor-critic family, but they differ in how they update the policy. A2C performs a direct policy-gradient update using the advantage estimate, while PPO introduces a clipped surrogate objective to make updates more conservative and stable.
Core formulation
π* = arg max_π E[ Σ_t γ^t r_t ]The agent learns a policy that maximizes expected discounted reward over time.
A(s_t, a_t) = Q(s_t, a_t) - V(s_t)The critic provides the baseline used to judge whether the selected action was better than expected.
L_A2C = - E[ log π_θ(a_t|s_t) · A(s_t, a_t) ]A2C updates policy directly using the advantage-weighted policy gradient.
L_PPO = E[min(r_t(θ)A_t, clip(r_t(θ), 1-ε, 1+ε)A_t)]PPO constrains policy changes with clipping, which improves optimization stability.
Practical comparison
A2C: simpler actor-critic update, lower algorithmic complexity, and strong early learning behavior. It is a good baseline for control-oriented resource allocation.
PPO: retains the actor-critic structure but adds policy-ratio clipping, which generally improves stability and makes learning less sensitive to large policy jumps.
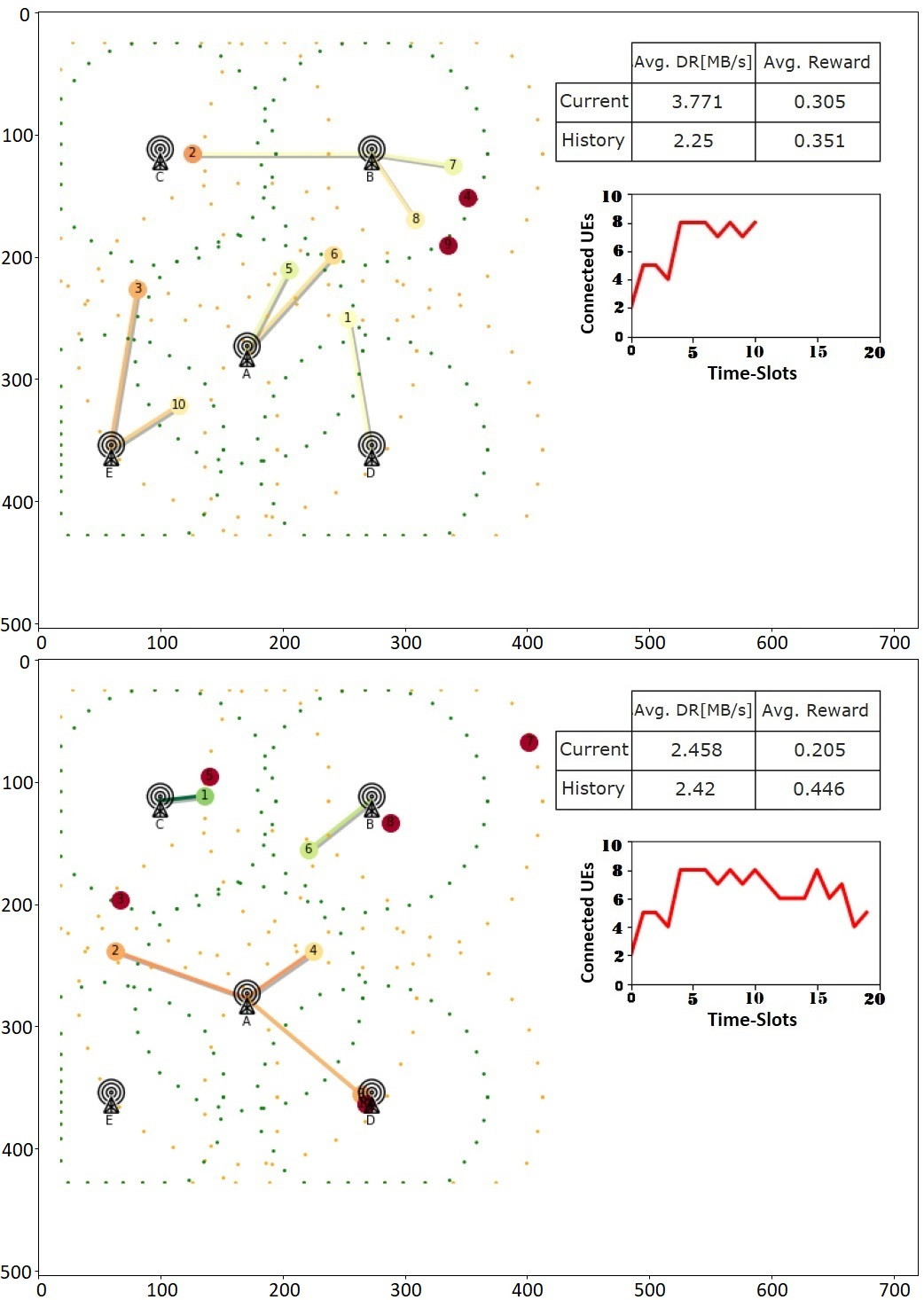
Why the comparison matters: in a near-RT RIC setting, convergence speed, reward stability, and robust scheduling behavior are just as important as final reward.
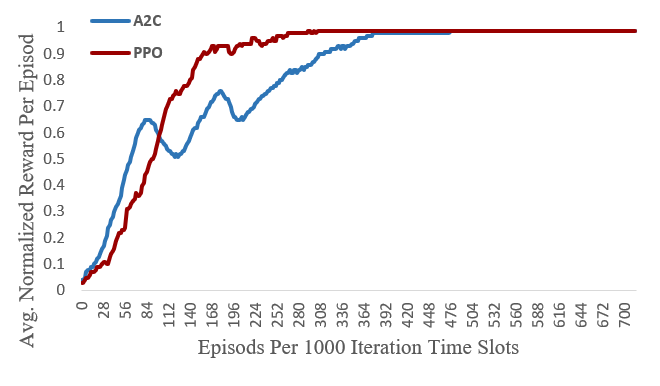
Observed behavior in this project: both models converge successfully, but PPO reaches the peak reward in fewer steps and maintains smoother optimization behavior.
A2C provides a compact and effective baseline, while PPO offers a stronger deployment candidate when training stability and safer policy improvement are priorities.